DeepMind just proved what many of us learned the hard way.
Their new research shows that unstructured “bag of agents” systems can amplify errors by up to 17×.
More LLMs ≠ better outcomes. In many cases, it’s just more noise.
When we started designing our platform, we faced the classic fork in the road:
– Add more generic models and hope for emergent intelligence?
– Or design a team with clear roles, guardrails, and feedback loops?
We chose architecture over brute force.
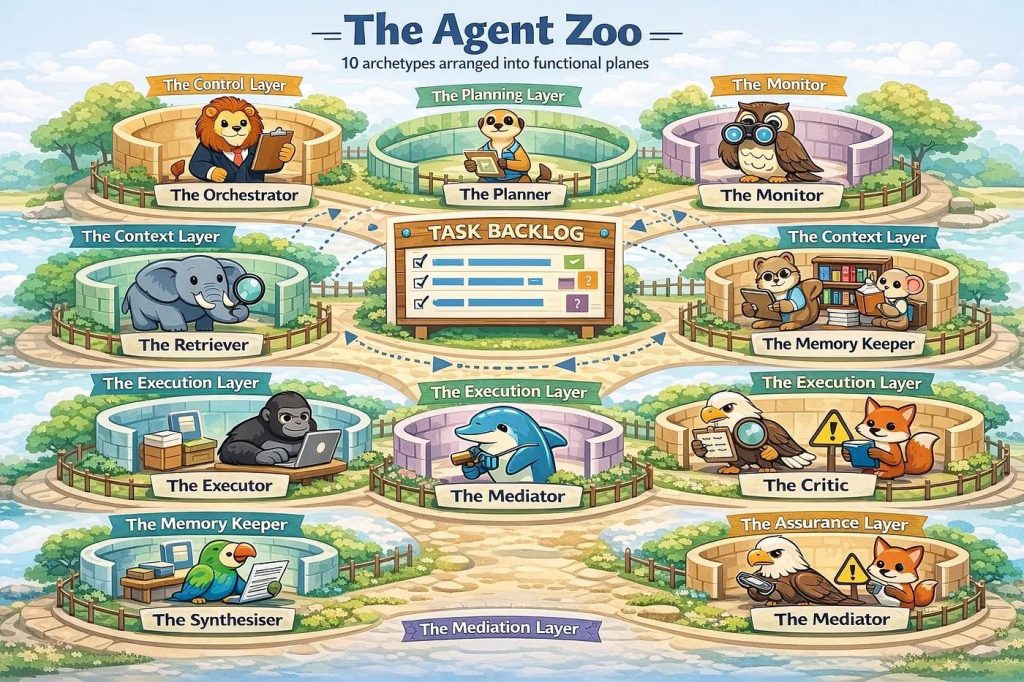
The paper “Towards a Science of Scaling Agent Systems” validates that decision almost line by line:
– Centralized orchestration beats swarm chatter
– Specialized agents outperform generalists
– Verification loops outperform fire-and-forget generation
– Multi-agent helps most when baseline accuracy is low; otherwise coordination tax eats the gains
These mirror the principles we embedded early:
✅ Orchestrator as decision maker
✅ Executors as narrow specialists
✅ Evaluators + critics as a closed-loop quality gate
✅ Retrieval as anti-hallucination grounding
This isn’t theory for us. We’ve seen what happens when these layers are missing—token burn explodes, logic drifts, and clients pay for expensive conversations instead of outcomes.
The future of agentic AI isn’t more agents.
It’s the right agents, arranged correctly, with accountability between them. Architecture wins.
admin
Content writer at BotPlus